※2016年10月1日より、サービス名称が「Yahoo!ビッグデータインサイト」から「トレジャーデータサービス by IDCF」に変更となっております。
「Yahoo!ビッグデータインサイト」は、一言でいうとビッグデータ分析のためのクラウドサービスです。 そのサービス名がちょっと長いので、社内外で「YBI」と略称で呼んでます。(最初の訪問でYBIと呼び始めると、お客さまも「YBI」と呼んでくれるのがうれしくなるw) YBIでは分析のための環境を一通り用意しており、「生のデータ」を用意して、データをインポートし、あとはお好きなように分析! というように明快なステップでビッグデータ分析を始める事ができます。
導入時サポートの1つとして過去データのインポートがあります。CSV形式などで持っている以前のデータセット一式を使って分析をしたい! って考えるでしょ?
この一括インポートには、コマンドラインツールによるバルクインポートを使うのが有効です。 しかし、コマンドラインツールを自分のサーバーにインストールしていただいて実行するため、サーバーの負荷はいったいどの程度になるのかご質問をいただくことも事実。 バルクインポートの実施方法は別の記事に譲ることとして、今日はバルクインポート実行時のサーバー負荷について検証した結果をご案内します。
バルクインポートって?
まず最初に軽くおさらい。 バルクインポートは、YBIへデータをインポートするための手段の1つで、既存の大容量データを一括でインポートするのに適した方法です。 tdコマンドラインツールを使用して実行します。
実行例
td import:auto \ --format csv \ --auto-create bulktestdb.importtest \ --column-header \ --time-column datetime \ --time-format "%Y-%m-%d %H:%M:%S" \ --parallel 2 \ --prepare-parallel 2 \ ./bulktestlog
オプションがいっぱいあってややこしいですね。 詳細についてはこちらの記事をご参照いただければと思います。 TreasureDataに既存データ(TSV形式)をバルクインポートしてみた
今回の検証条件
データの中身
Webのアクセスログと同等の内容を含んだCSVファイル(bulktestlog)を用意しました。
$ wc bulktestlog 10000001 135630065 1879761639 bulktestlog $ head -1 bulktestlog datetime,host,path,method,code,referer,agent
1,000万と1行、約1.3億の単語数、約1.9GBのデータを用意しました。 1行目はヘッダ行のため、実データはちょうど1,000万件です。
サーバー環境
IDCFクラウドに仮想マシンを作成して実行します。OSは、CentOS 6.6 64bitで実施しました。 仮想マシンサイズを3種類で比較してみます。
- standard.M8 (2CPUx2.4GHz, 8GB RAM)
- highcpu.L8 (4CPUx2.6GHz, 8GB RAM)
- highmem.M16 (2CPUx2.2GHz, 16GB RAM)
測定方法
まず、td import:autoコマンドのターンアラウンドタイムは、Linuxのtimeコマンドで計測します。 また、バルクインポート実施中のサーバー負荷の計測には、
[メモリ状況]freeコマンドでbuffers/cache考慮後のfreemem、
[CPU状況]mpstatコマンドで得られる%usrと%idleを用いることにします。(複数コアのトータルの値)
$ free
total used free shared buffers cached
Mem: 8053600 3079032 4974568 144 31264 2828792
-/+ buffers/cache: 218976 7834624 (←freeの値)
Swap: 0 0 0
$ mpstat 1
11:32:56 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
11:32:57 all 0.99 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.01
↑ ↑
結果
バルクインポート実行時間
それぞれ3回以上バルクインポートを実施した平均実行時間は次の通りでした。
| 仮想マシンサイズ | 平均実行時間 | |
|---|---|---|
| 並列度1 | 並列度2 | |
| standard.M8 (2CPUx2.4GHz, 8GB RAM) | 3m15.994s | 4m16.466s |
| highcpu.L8 (4CPUx2.6GHz, 8GB RAM) | 3m09.036s | 3m21.132s |
| highmem.M16 (2CPUx2.2GHz, 16GB RAM) | 3m13.532s | 4m47.262s |
並列度は、--parallelおよび--prepare-parallelのオプションで指定できます。 今回は単一ファイルのバルクインポートを実行しており、並列度1の方が早く完了しました。 また、並列度1では仮想マシンサイズによる差はあまり見られませんが、並列度2ではhighcpu.L8が最も早く完了しました。higicpu.L8の仮想マシンはCPUクロック数が他よりも速いので、それが効いているように思います。
CPU使用率とメモリ使用量
仮想マシンのサイズ毎に、CPU使用率とメモリ使用量の推移をグラフに表しました。 いずれも並列度を1にした時の様子です。
・standard.M8 (2CPUx2.4GHz, 8GB RAM) 並列度1 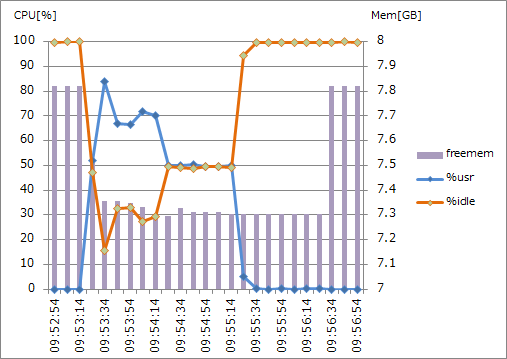
・highcpu.L8 (4CPUx2.6GHz, 8GB RAM) 並列度1 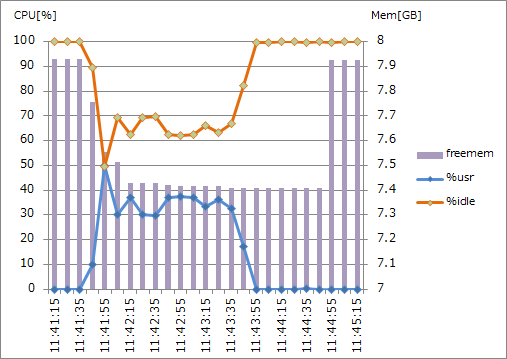
・highmem.M16 (2CPUx2.2GHz, 16GB RAM) 並列度1 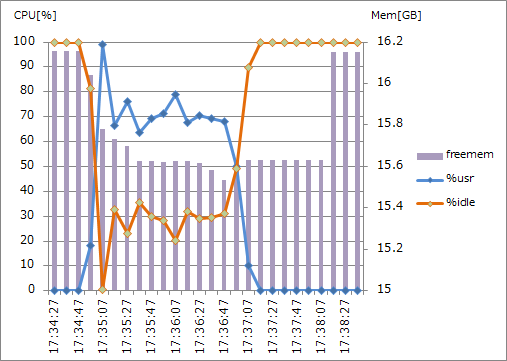
CPU使用率は、バルクインポート開始時に一旦跳ね上がった後、少し低い位置で推移しています。同じタイミングでメモリ使用も始まっています。 また、CPU使用が終了した後、しばらくはメモリ使用されている状態が継続しています。 これは、転送用ファイル(msgpack)作成の際にCPUとメモリが使用され、続くファイル転送の際にはメモリだけが使われているようです。
続いて並列度を2にした場合の様子です。
・standard.M8 (2CPUx2.4GHz, 8GB RAM) 並列度2 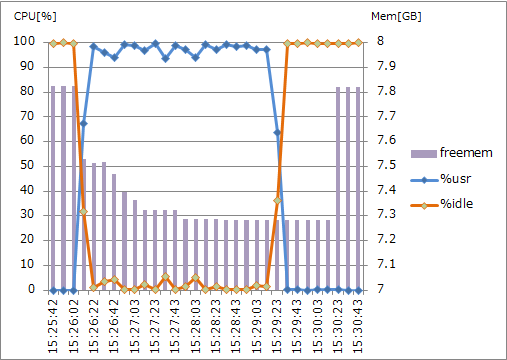
・highcpu.L8 (4CPUx2.6GHz, 8GB RAM) 並列度2 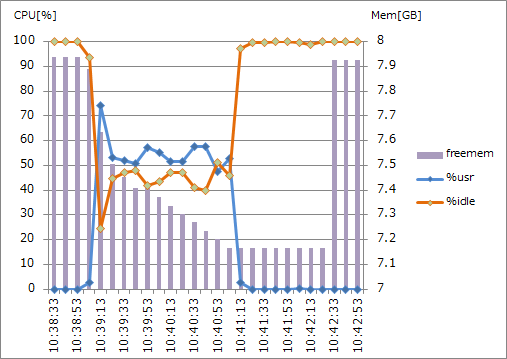
・highmem.M16 (2CPUx2.2GHz, 16GB RAM) 並列度2 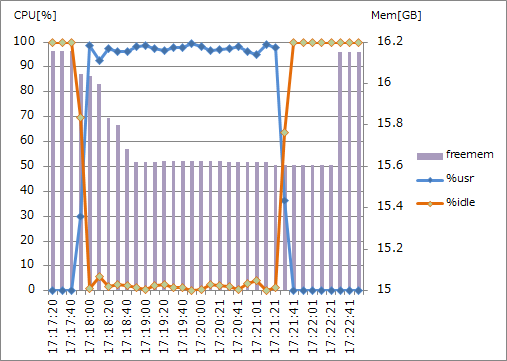
CPUコア数が2であるstandard.M8とhighmem.M16の仮想マシンでは、%usrが100%近くまで到達しました。一方でCPUコア数4のhighcpu.L8の仮想マシンでは、50%近くでとどまっています。バルクインポートでは、CPUリソースを最大限近くまで使おうとしているのでしょう。
まとめ
今回の検証では、次のような結果となりました。
- メモリ搭載量が同じの場合、CPUクロック数が速い仮想マシンでは、バルクインポート実行時間は短くなる
- CPUコア数が同じの場合、メモリ搭載量によってバルクインポート実行時間にそう大きな差は出ない
- 単一ファイルのバルクインポートでは、並列度を少なくした方が実行時間は短くなる
- CPUは、前準備のステップで使用される (下記※参照)
- メモリは前準備からアップロードのステップで使用される (下記※参照)
(※) バルクインポートの処理では、前準備としてデータを分割してmsgpack形式へ圧縮し、アップロードを行い、YBI内部の処理でファイルのインポートとテーブルへのデータ反映をしています。
バルクインポートを実行するサーバーにはCPUクロック数が速いものを準備するのが良いでしょう。 また、バルクインポート実行時にはCPUリソースを目一杯使うことになるので、並列度はCPUコア数よりも少ない程度で調整すると、他のプロセスへの影響を抑えられそうです。
検証してみて、複数ファイルをバルクインポートする時のサーバーリソースはどうなのか、疑問が湧いてきました。これは、引き続き検証したいと思います。