今回のテーマは Kubernetes 環境におけるコンテナ(アプリケーション)のログについてです。Docker と Kubernetes でのロギングについておさらいした上で、IDCFクラウド コンテナでログ収集の仕組みを実際に構築してみます。
背景
本番環境で調査のためにローカルディスクへ書かれたログを tail で眺めるなど当然のようにやっていると思いますが、コンテナ環境においてはコンテナへ SSH で入ること自体が推奨されませんし、コンテナが破棄された時点でノード上に出力されたログも削除されてしまいます。また、マイクロサービス的なアプローチの場合、一つのサービスのログだけを見ていても処理の流れが見えてきません。複数のログを横断的に調べる仕組みが求められます。
よって、ログを Elasticsearch、Loki、S3/GCS などのストレージで永続化し、Kibana、Grafana、BQ などで検索・可視化するケースも多いと思います。そのようなロギング構成はどのように構築するべきでしょうか。
おさらい
まずは Kubernetes における標準的なログ機構について、公式サイトに書かれている内容をおさらいしておきます。Kubernetes は Docker のログ機構に基づいているのでまずは Docker のログの仕組みからおさらいします。 *1
Docker Logging(Docker v19.03)
Docker には標準で logging driver という仕組みが備わっています。
http://docs.docker.jp/v19.03/config/container/logging/index.html
コンテナから標準出力やエラー出力に出されたログが、設定した logging driver によって処理されます。
| ドライバ | 説明 |
|---|---|
| none | コンテナに対するログを記録せず、 docker logs は何も出力しません。 |
| local | ログは最小のオーバヘッドになるよう設計されたカスタム形式で記録します。 |
| json-file | JSON 形式でログを記録します。Docker のデフォルトのロギング・ドライバです。 |
| syslog | syslog ファシリティに対してロギング・メッセージを記録します。ホスト・マシン上で syslog デーモンの起動が必要です。 |
| journald | ログメッセージを journald に記録します。ホスト・マシン上で journald デーモンの起動が必要です。 |
| gelf | ログメッセージを Graylog または Logstach などのような Graylog Extended Log Format (GELF) エンドポイントに記録します。 |
| fluentd | ログメッセージを fluentd に記録(forward input)します。ホスト・マシン上で fluentd デーモンの起動が必要です。 |
| awslogs | ログメッセージを Amazon CloudWatch Logs に記録します。 |
| splunk | HTTP Event Collector を使い、 splunk にログメッセージを記録します。 |
| etwlogs | Event Tracing for Windows (ETW) events としてログメッセージを記録します。Windows プラットフォーム上で利用可能です。 |
| gcplogs | Google Cloud Platform (GCP) ロギングにログメッセージを記録します。 |
| logentries | Rapid7 Logentries に対してログメッセージを記録します。 |
上記以外に Plug-in で追加も可能で、Docker デーモン全体、またはコンテナごとに設定することができます。デフォルトは json-file になっており、json-file や journald では docker logs コマンドでログの内容が参照できます。
Kubernetes logging(Kubernetes v1.19)
Kubernetes においては、まずコンテナを実行するコンテナランタイムがコンテナの出力するログを取り扱うことになります。よってコンテナランタイムが Docker の場合、先ほど説明した Docker の logging driver の仕組みでログが取り扱われます。logging driver が json-file の場合、ノード上に出力された後に Kubernetes として kubectl logs コマンドでログの内容が参照できるようになります。
https://v1-19.docs.kubernetes.io/docs/concepts/cluster-administration/logging/
上記ページで紹介されているロギングの構成を以下にまとめておきます。 *2
(1) ノードレベルロギング(標準のログ機構)
まずノード単体でのシンプルなロギングについてです。コンテナから標準出力とエラー出力に出力されたログがノード上のログファイルに書き込まれます。
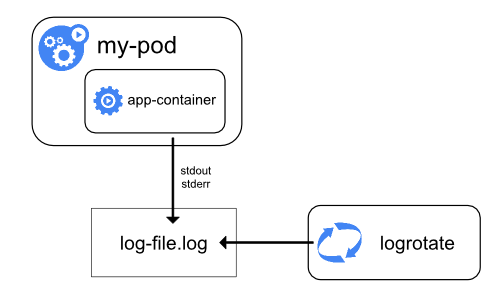
コンテナがノードから追い出されるとログも消えてしまうので永続化や可視化をする場合、外部サービス(Logging Backend)に送る必要があります。Logging Backend に送る方法を検討してみましょう(公式ページでは「クラスターレベルロギング」と名付けられています)。
(2) クラスターレベルロギング
(2-1) ノードごとにロギングエージェントを配置
まずは各ノードごとにロギングエージェントを仕込む方法です。
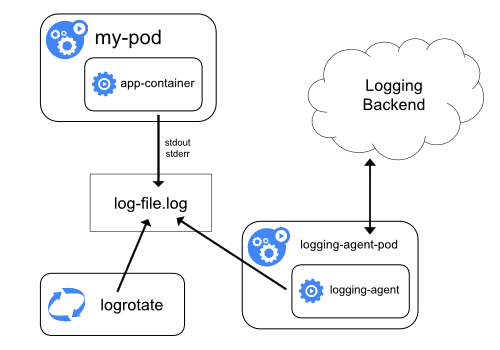
(2-2) サイドカーで複数ログを扱う
アプリケーションによっては出力先が(標準出力やエラー出力ではなく)ファイルだったり、異なるフォーマットのログを複数出力したい場合もあるでしょう。そんな場合はポッド内にログストリームを扱うサイドカーコンテナを埋め込み、サイドカーでストリームをコントロールします。
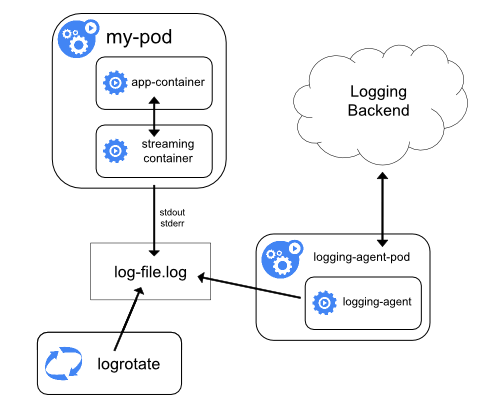
(2-3) サイドカー自身で外部に送信
各ポッドのサイドカー自身で外部にログを送信してしまう方法もあります。
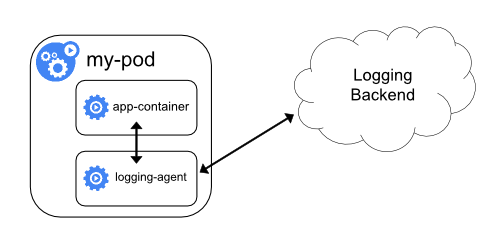
(2-4) アプリケーション自身で外部に送信
もちろんサイドカーに依頼せずアプリケーション自身で外部に送信する仕組みを実装することも可能です。
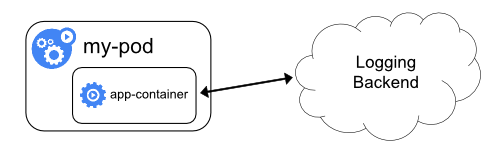
ロギング方式の考察
さきほどご紹介した(1)ノードレベルロギングだけではコンテナが追い出された時点でログも消えてしまいます。信頼性や可用性を求められないシステムであれば問題ありませんが、ミッションクリティカルなシステムの場合、外部へのログ送信は必須となるでしょう。
また、(2-3)ポッドごとにサイドカーを埋め込むのは浪費的ですし、(2-4)アプリケーション自身で送信するのは開発者の負担が大きいため、一般的なシステムにマッチしやすいのは(2-1)ノードごとにロギングエージェントを配置する構成ではないでしょうか。
IDCF クラウドコンテナで構築してみる
それでは(2-1)ノードごとにロギングエージェントを配置する構成をIDCFクラウド コンテナの「for IDCFクラウド」で構築してみます。
構成
(2-1)ノードごとにロギングエージェントを配置する構成として下記のような構成を想定しています。
- アプリケーションは標準出力にログを出力
- Docker logging / json-file が上記の出力をノード上のディスクに書き出す
- 各ノードごとに1つ fluentd-forwarder を動かして fluentd-aggregator に転送
- fluentd-aggregator 上の filter 設定で加工
- 加工後、永続化ストレージや可視化ツールに転送
- fluentd-aggregator は送信先が障害等で送信できない場合にバッファリング
- スタンバイ中継サーバを用意し、メインの中継サーバが障害の場合に昇格
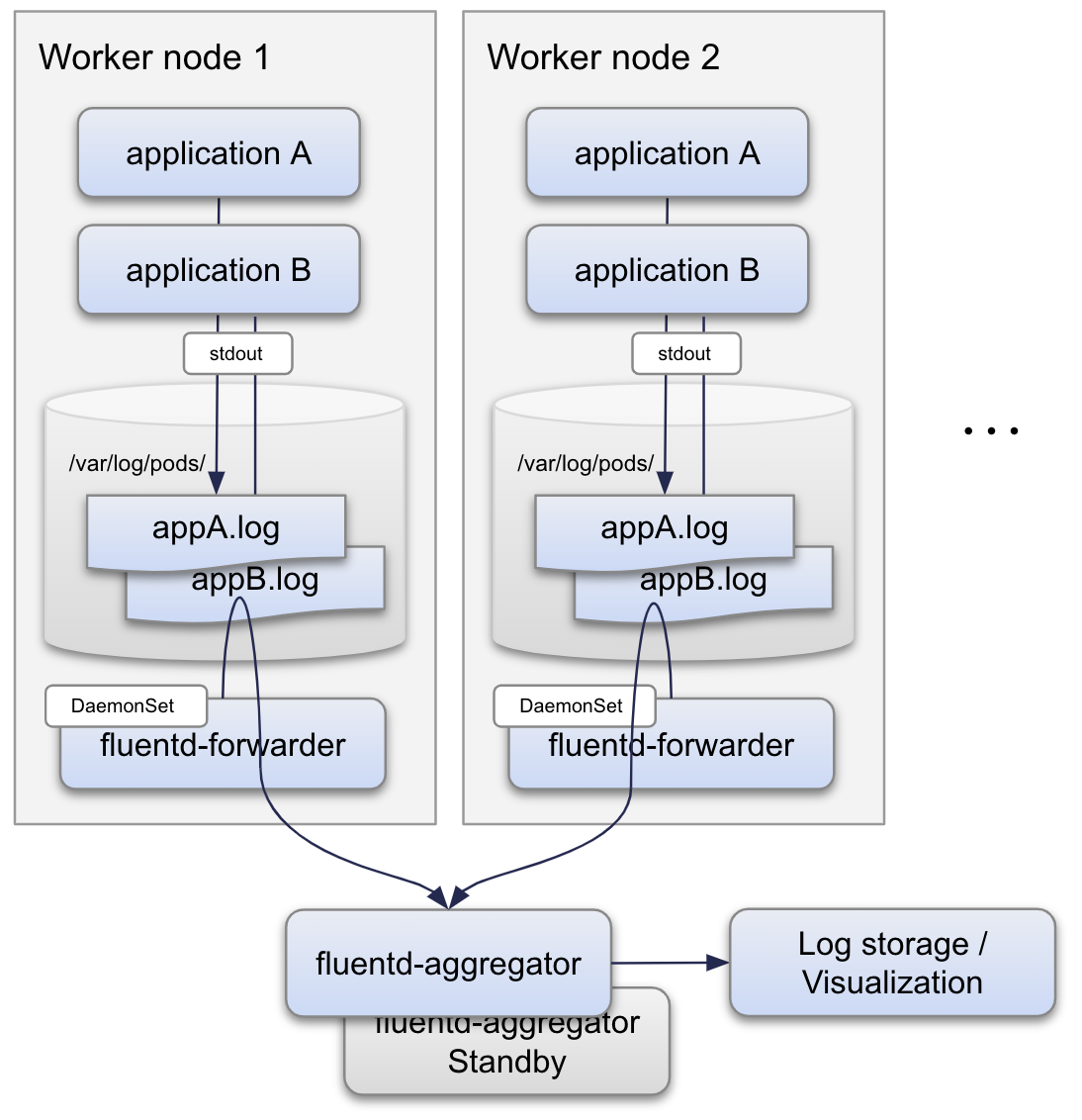
想定構成
上記想定構成の構築方法を理解するにあたって、今回はシンプルに下記構成で構築してみます。
- (アプリケーションログの代わりに)nginx を立ててアクセスログを標準出力に出力
- Docker logging / json-file がノードのディスクに書き出す
- 各ノードごとに1つ fluentd-forwarder を動かして fluentd-aggregator に転送
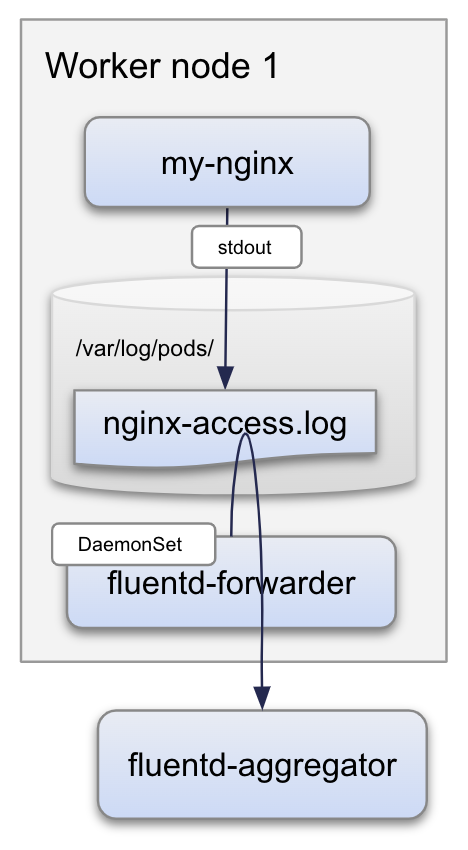
今回の構成
実際の手順
事前準備
IDCFクラウド コンテナの for IDCFクラウドでIDCFクラウド上にクラスターを構築し、初期設定(IDCFクラウドAPIにアクセスするためのシークレット情報を登録)をしておきます。 *5 *6 *7
nginx の構築
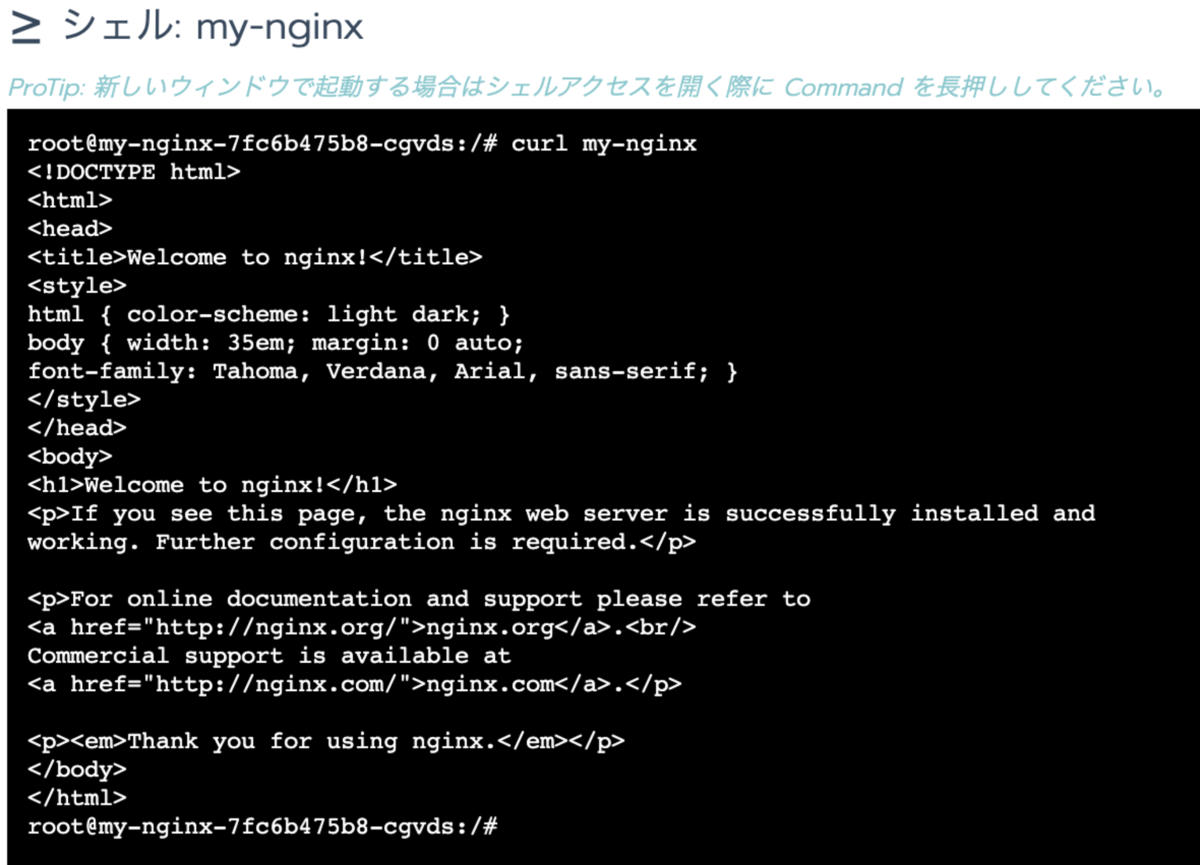
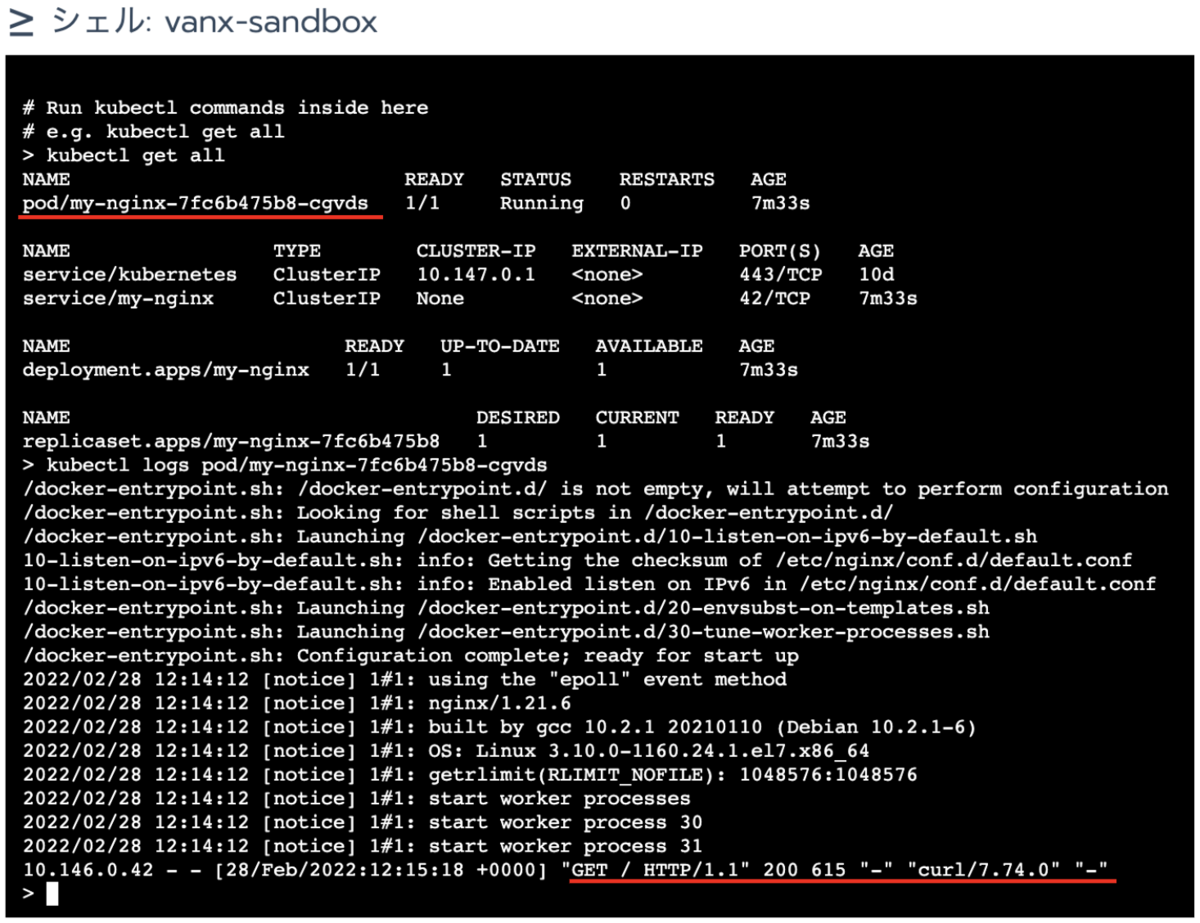
ログを出力するアプリとして my-nginx を動かします。Default プロジェクトのリソース>ワークロードから nginx の公式イメージをデプロイします。
作成したコンテナに curl でアクセスすると access log がノード上の /var/log/pods/ (実体は /var/lib/docker/containers/ )の中に出力されます。
fluentd-aggregator の構築
ノード上のログを転送する fluentd-forwarder を構築する際にログ転送先の fluentd-aggregator のアドレスが必要になるので先に fluentd-aggregator を構築します。 Default プロジェクトのリソース>ワークロードから fluentd の公式イメージをデプロイします。
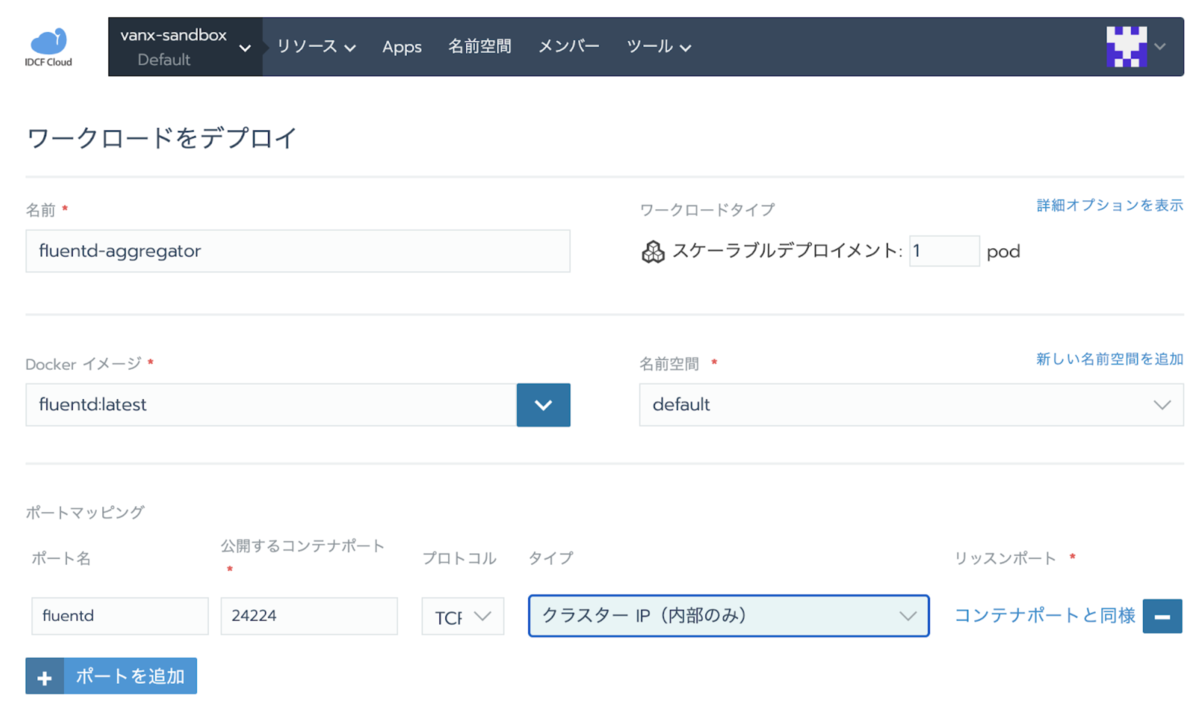
お試しなのでヘッドレスにして名前でアクセスしてもいいのですが ClusterIP を取得しておきます。 *8
fluent-cat で fluentd-aggregatpr の ClusterIP 宛に送って動作確認をしておきます。

fluentd-forwarder の構築
後ほど説明しますが事前準備としてリソース>ワークロード>サービスディスカバリで先程構築した fluentd-aggregator の ClusterIP のIPアドレスをひかえておきます。
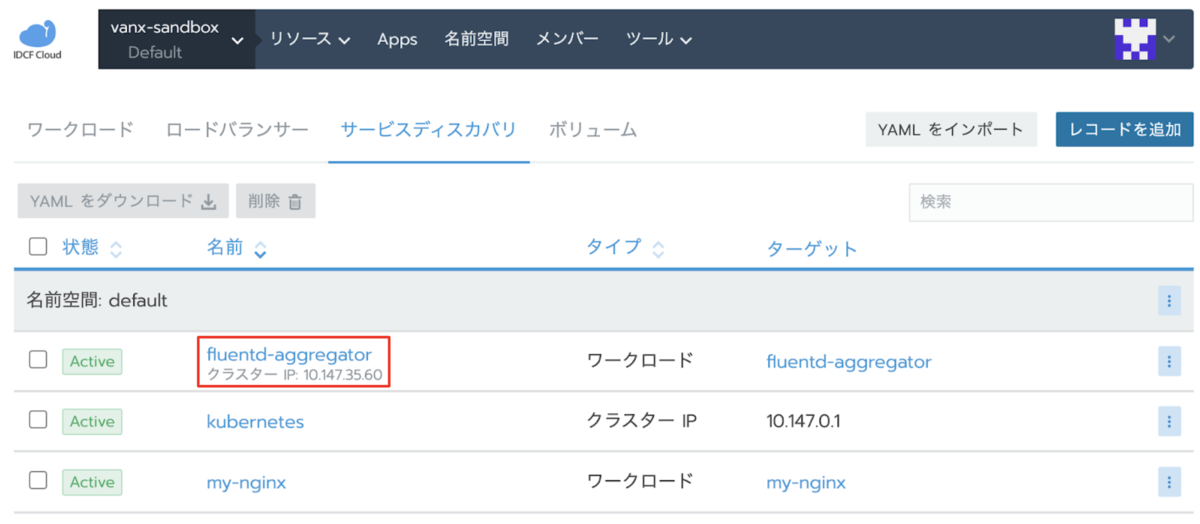
fluentd-forwarder を各ノードに一つずつ動かしたいので Fluentd を DaemonSet で動かそうと思うのですが、IDCFクラウド コンテナの場合、画面上でロギングを有効化するだけで当該構成が構築できます。 *10
ツール>ログ画面で Fluentd を選び、転送先の fluentd-aggregator の情報を入力します。ここでエンドポイントを fluentd-aggregator:24224 などとしたいところですが、画面上ではIPアドレスしか登録できないので先程取得した fluentd-aggregator の ClusterIP を入力します。
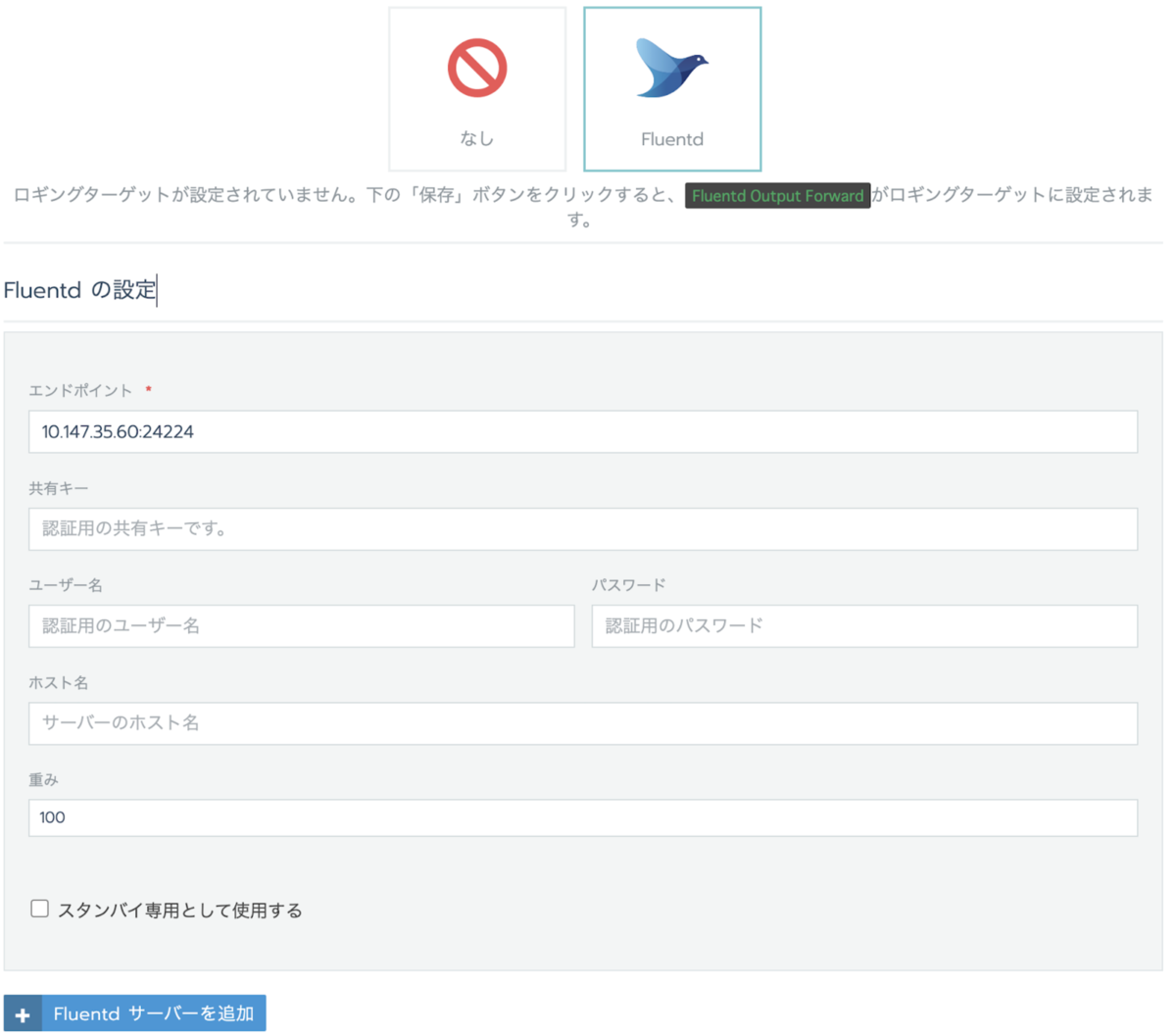
また、この画面ではフォームを使わずに Fluentd の conf ファイルを直接編集することも出来ます(直接編集であればエンドポイントもFQDNで指定できそうです)。画面下部の「テスト」は Dry Run で実行することで conf の syntax をチェックしています。 *11
Fluentd サーバーを複数立てることで冗長化が可能です。「スタンバイ専用として使用する」にチェックを入れるとスタンバイ専用として扱われ普段はアクセスされません。
確認
nginx にアクセスし、アクセスログが fluentd-aggregator まで届くか確認してみましょう。
curl で http://my-nginx/HelloWorld にアクセスします。
(少々分かりづらいですが)HelloWorld へのアクセスが fluentd-aggregator 内のログに書かれました。

これで fluentd-aggregator への転送まで完了しました。今回は割愛しましたが、fluentd-aggregator から外部のストレージや可視化ツールへの送信は送信先に応じて fluentd-aggregator で設定してください。Fluentd にはプラグインが豊富に用意されていますので容易に転送設定が可能です。
その他留意点
ログのローテーション
ログといえばローテーションがつきものです。ログが増え続けてディスクを圧迫し始めると Kubernetes は優先度が低く使用量の多い Pod を削除します。同時に未転送のログも削除されてしまうためローテーションの設定をしておきたいですね。
Docker Logging driver が json-file の場合、log-opts で max-size や max-file を設定することでローテーションがされます。また、Kubelet の Config で containerLogMaxSize や containerLogMaxFiles を指定することでもローテーションされます。ローテーションされたログは kubectl logs --pervious で参照できますがローテーションで削除されると参照できません。
なお、for IDCFクラウドのノードでは Docker logging の設定でローテーション設定がされています。
ログの欠損を減らす
ログは異常時にこそ必要なのですが、その異常時にこそ失われるものです。下記のような点を考慮してログが欠損しづらい構成にしておきましょう。
- fluentd-aggregator を冗長構成にしておく
- ログはなるべく早く欠損しづらい場所へ送る(flush_interval, flush_at_shutdown などの値を見直す)
- 送信できない場合に備える(file_buffer, require_ack_response, retry_limit などの値を見直す)
最後に
Kubernetes の手軽さをIDCFクラウド コンテナがさらに引き立てていることをご理解いただけたと思います。
なお、今回ご紹介したIDCFクラウド コンテナのロギング機能は今後さらなるバージョンアップを予定しています。次バージョンでは Banzai Logging Operator を導入することでロギングパイプラインを構築できるようになります。CRs の yaml でログフローを定義できるため、GitOps 化がはかどりそうです。
バージョンアップされ次第また改めてこのブログでご紹介いたしますのでご期待ください。
*1:2022年2月28日の情報です。
*2:以下は logging driver が標準の json-file に設定されているものとします。
*3:実際のログのファイル名はランダムな文字列ですが便宜的に「appA.log」としています。
*4:実際のログのファイル名はランダムな文字列ですが便宜的に「nginx-access.log」としています。
*5:今回利用した Kubernetes version: v1.19.15
*6:手順はご利用ガイドを参照してください https://www.idcf.jp/help/container/guide/
*7:for IDCFクラウドで構築されたノードの Docker logging driver は json-file になっていますが、オンプレミス(for カスタム)等で自分で Docker 環境を用意した場合は json-file になっているか確認してください。CentOS 7 の yum で Docker-CE を入れたら jounald になっていました。
*8:fluentd のデフォルトのポート番号は 24224
*9:ハマリポイントメモ:コンテナ内での Service 名の名前解決は resolv.conf の search ドメインで補完されているので dig で名前解決する場合は +search の指定が必要でした。
*10:クラスターごと、またはプロジェクト単位で設定できます。
*11:エンドポイントへの到達性まではチェックしていません。
*12:Fluentd のプロセスにシグナルを送ることで flush することも可能です。