こんにちは、藤城(@tafujish)です。
最近、生成AIをはじめAIとそれを動かすGPUの拡がりはすごいですね。
大規模なAIを独自に開発・利用するには、GPUを活用した大規模なITインフラの構築が必要になります。実際、IDCフロンティアのデータセンターを活用した例が続いてます。
IDCフロンティアでは、AIを活用し新サービスや研究を行う企業やアカデミックの方向けに「AI開発推進プログラム」の提供を開始しました。
www.idcf.jp
そこで、今回は「AI開発推進プログラム」にて無償提供しているIDCFクラウドのgpu.7XLP100上で、大規模かつオープンな日本語LLMであるOpenCALMを動かす方法をご紹介したいと思います。
GPUを搭載したVMを作成
まずは、IDCFクラウド上で、GPUを搭載したVMを作成します。
GPUを搭載したマシンタイプは、本記事公開時点で東日本リージョン2での提供のみとなります。
https://console.jp-east-2.idcfcloud.com/compute/vm/
参考) リージョンの有効化方法を教えてください
参考) ゾーン追加の方法
(東日本リージョン2が利用できない場合は、利用希望の旨をサポートまでお問い合わせください)
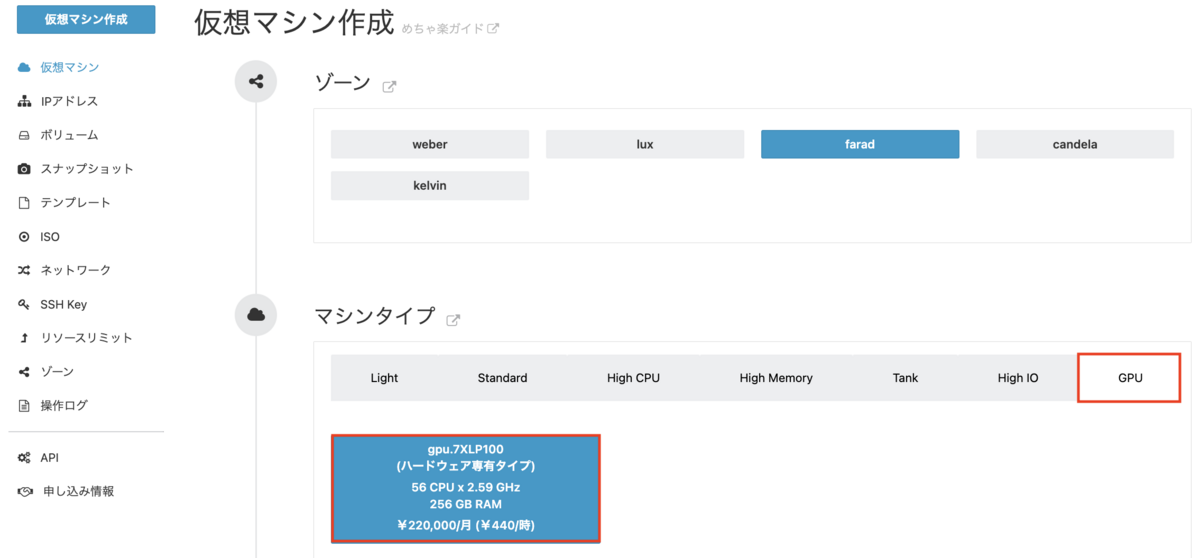
それでは、仮想マシン作成を進めていきます。マシンタイプでは「GPU」タブにある「gpu.7XLP100」を選択します。
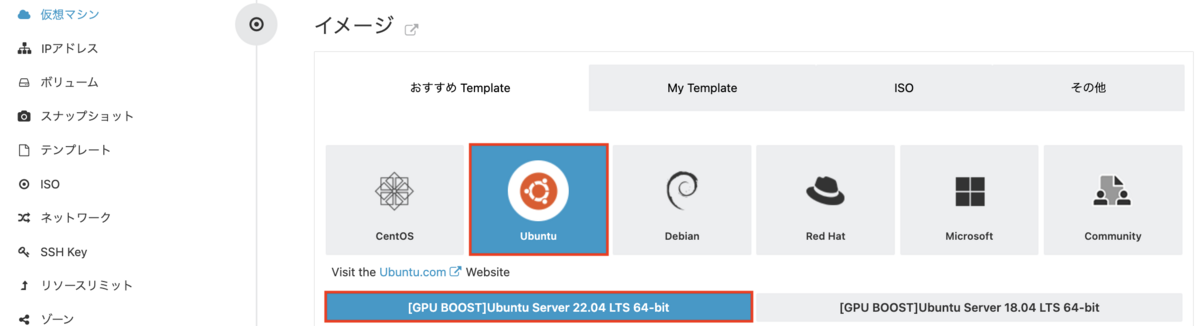
イメージでは、「Ubuntu」タブにある「Ubuntu 22.04」を選択します。
SSH Keyではご自身のキーを設定し、仮想マシン名を入力すれば、確認の後、作成開始となります。
あとは、IPアドレスからSSH用のポートをポートフォワードすれば完了です。
GPU実行環境を構築
次に、作成したVMにSSHログインし、CUDAをインストールしましょう。
CUDA(ツールセットとドライバー)をネットワークインストールして、パッケージが入ったらOS再起動します。
# apt update # apt install cuda -y # reboot
OS再起動後、再度SSHログインし、GPUが認識できているか確認します。
# nvidia-smi
Sat Dec 1 12:01:00 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla P100-PCIE-16GB On | 00000000:14:00.0 Off | 0 |
| N/A 37C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
LLMを実行
本題のOpenClamを動かしていきましょう。OpenClamは、学習済みモデル等の共有プラットフォームであるHugging Face Hub上で公開されていますので、簡単に動かすことができるようになっています。
モデルサイズ(パラメータ数)の違いなどいくつかのモデルが公開されていますが、今回はOpenCalmより新しいCALM2-7Bを動かしてみましょう。
まずは、必要な(Requirementsの項目にある)パッケージをインストールしていきます。ここではpipを使います。
# apt install python3-pip -y # pip3 install transformers torch torchvision accelerate
実際にコードを実行していきましょう。サンプルとなるコードがUsageのところにあるので、これをsample.pyという名前のファイルにコピペします。
【sample.py】
import transformers from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer assert transformers.__version__ >= "4.34.1" model = AutoModelForCausalLM.from_pretrained("cyberagent/calm2-7b", device_map="auto", torch_dtype="auto") tokenizer = AutoTokenizer.from_pretrained("cyberagent/calm2-7b") streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True) prompt = "AIによって私達の暮らしは、" token_ids = tokenizer.encode(prompt, return_tensors="pt") output_ids = model.generate( input_ids=token_ids.to(model.device), max_new_tokens=100, do_sample=True, temperature=0.9, streamer=streamer, )
では、実行していきましょう。初回はモデルのダウンロードが入るので、多少時間がかります。2回目以降は更新がなければスキップされます。
# python3 ./sample.py pytorch_model.bin.index.json: 100%|█████████████████████████████████| 23.9k/23.9k [00:00<00:00, 113MB/s] pytorch_model-00001-of-00002.bin: 100%|█████████████████████████████| 9.98G/9.98G [00:46<00:00, 216MB/s] pytorch_model-00002-of-00002.bin: 100%|█████████████████████████████| 4.04G/4.04G [00:18<00:00, 217MB/s] Downloading shards: 100%|███████████████████████████████████████████| 2/2 [01:06<00:00, 33.05s/it] Loading checkpoint shards: 100%|████████████████████████████████████| 2/2 [00:09<00:00, 4.55s/it] generation_config.json: 100%|███████████████████████████████████████| 132/132 [00:00<00:00, 1.22MB/s] tokenizer_config.json: 100%|████████████████████████████████████████| 674/674 [00:00<00:00, 6.19MB/s] tokenizer.json: 100%|███████████████████████████████████████████████| 3.27M/3.27M [00:00<00:00, 3.90MB/s] special_tokens_map.json: 100%|██████████████████████████████████████| 585/585 [00:00<00:00, 5.18MB/s] どんどん便利になっていきます。 しかし、便利になる反面、その便利さが問題になっていることをご存知でしょうか? 例えば、私達の生活に欠かせない存在となりつつあるスマートフォンですが、その便利さの裏側で、個人情報の漏洩やハッキング問題、SNSによる未成年への性被害などが多発し、問題視されています。 また、AIは便利だけではなく、多くの危険も孕んでいることを知る必要があります。 AIを搭載したロボットに仕事を奪われる未来が迫っていることはご存知でしょうか # python3 ./sample.py Loading checkpoint shards: 100%|████████████████████████████████████|2/2 [00:09<00:00, 4.83s/it] 生活全般が「効率化され」、「便利になって」いますが、その反面多くの危険と不安を抱え込むことになってしまっています。 現在、AIによる自動車、IoT家電、介護ロボット、ロボット、スマートグリッドなど、あらゆる領域でAIは活用されてきていますが、AIが人間に取って代わるのではなく、「人間とAIが共生していく」時代の到来も考えられます。 そして、このような社会において、ますます重要になっていくのが「倫理観」です。AIは人間より賢いと
むすび
以上で無事に実行できました、簡単でしたね。では、次にpromptの内容を変えて実行してみてください。
ちなみに、今回使用したGPUは、NVIDIA P100となりGPU搭載のメモリは16GBになります。モデルサイズが7Bだと14GB弱メモリを消費しますので、7B以下のモデルしか実行できません。もし、これより大きいモデルを実行するには、よりメモリを多く搭載したGPUが必要となります。
いかがでしたでしょうか。
IDCFクラウドへのGPUの要望(モデル、メモリサイズ、金額感)お待ちしております。どうぞお気軽にお知らせください。